WebVision Dataset 1.0
The WebVision dataset is designed to facilitate the research on learning visual representation from noisy web data. Our goal is to disentangle the deep learning techniques from huge human labor on annotating large-scale vision dataset. We release this large scale web images dataset as a benchmark to advance the research on learning from web data, including weakly supervised visual representation learning, visual transfer learning, text and vision, etc. (see recommended settings for the WebVision dataset).
The WebVision dataset contains more than 2.4 million of images crawled from the Flickr website and Google Images search. The same 1,000 concepts as the ILSVRC 2012 dataset are used for querying images, such that a bunch of existing approaches can be directly investigated and compared to the models trained from the ILSVRC 2012 dataset, and also makes it possible to study the dataset bias issue in the large scale scenario. The textual information accompanied with those images (e.g., caption, user tags, or description) are also provided as additional meta information. A validation set contains 50,000 images (50 images per category) is provided to facilitate the algorithmic development. The preliminary results of a simple baseline show that the WebVision dataset is able to learn robust representation which achieves comparable performance as the model learnt from the human annotated ILSVRC 2012 dataset on several vision tasks.
Paper
Dataset Details
Statistics
The number of images per category for our dataset is shown in Fig 1, which varies from several hundreds to more than 10,000. the number of images per category depends on: 1) the number of queries generated from the synset for each category 2) the availability of images on the Flickr and Google.
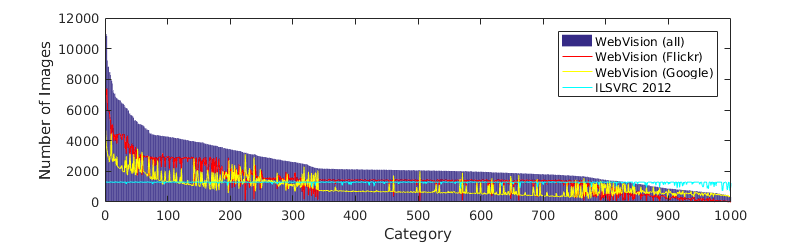
Figure 1
The number of images per category of the WebVision dataset.
Evaluation of Simple Baseline
We investigate the capacity of web data for learning visual representation by using a simple baseline. We combine the queried images from Flickr and Google Image as our training dataset, and train the AlexNet models on this training set from scratch. Then we evaluate the learnt AlexNet model for the image classification task on the Caltech-256 dataset and the PASCAL VOC 2007 dataset, and object detection on the PASCAL VOC 2007 dataset.
Image Classification
We investigate the capacity of web data for learning deep networks by using a simple baseline. We train the AlexNet models from scratch on the WebVision training set and ILSVRC 2012 dataset, respectively, and then evaluate the two models on the WebVision validation set and the ILSVRC 2012 validation set. Note that no human-annotated data is used when training model on the WebVision dataset. The top-5 (and top-1) accuracies are reported here.
The results show that: 1) The CNN models trained using the WebVision dataset achieves competitive performance with the human annotated ILSVRC 2012 dataset; 2) A dataset bias is observed, i.e., the model trained on WebVision is better than the one trained on ILSVRC 2012 when evaluating on the WebVision Validation set, and vice versa. This would be an interesting issue for researchers in domain adaptation field.
Image Classification Results
|
Test Data |
|||
|
WebVision Val |
ILSVRC 2012 Val |
||
|
Training Data |
WebVision |
77.90 (57.03) |
70.36 (47.55) |
|
ILSVRC 2012 |
74.64 (52.58) |
79.77 (56.79) |
|
Transfer Learning Classification Results
| Caltech-256 | PASCAL 2007 | |
|---|---|---|
|
ILSVRC 2012 |
70.44 |
75.65 |
|
WebVision |
70.43 |
77.78 |
|
WebVision + ILSVRC 2012 |
73.61 |
78.46 |
Transfer Learning Image Classification
We further evaluate the learnt AlexNet model for the image classification task on the Caltech-256 dataset and the PASCAL VOC 2007 dataset.
For the Caltech-256 dataset, 30 images per category are used as the training set and the rest as the testing set. For PASCAL-VOC 2007 dataset, we combine the official train and validation splits as the training set, and use the test split as the test set.
For all CNN models, we use the 4096-d output from the "fc7" layer as the feature representation, and train SVMs using the training set. Accuracy and mAP are respectively reported for Caltech-256 and PASCAL VOC 2007 datasets.