LSDIR Dataset: A Large Scale Dataset for Image Restoration


Abstract
We collected a large-scale dataset for image restoration tasks such as image super-resolution (SR), image denoising, JPEG deblocking, deblurring, and demosaicking, and real-world SR.
The aim of this project is to propose a large scale dataset for image restoration (LSDIR). Recent work in image restoration has focused on the design of deep neural networks. The datasets used to train these networks ‘only’ contain some thousands of images, which is still incomparable with the large scale datasets for other vision tasks such as visual recognition and object detection. The small training set limits the performance of image restoration networks. To solve that problem, we collect high-resolution (HR) images from Flickr for image restoration. To ensure the pixel-level quality of the collected dataset, annotators were invited to manually inspect each of the collected image and remove the low-quality ones. The final dataset contains 84,991 high-quality training images, 1,000 validation images, and 1,000 test images. In addition, we showed that the model capacity of large networks could be fully exploited by training on the large scale dataset with significantly increased patch size and prolonged training iterations. The experimental results on image SR, denoising, JPEG deblocking, deblurring, and demosaicking, and real-world SR show that image restoration networks benefit a lot from the large scale dataset.
Results
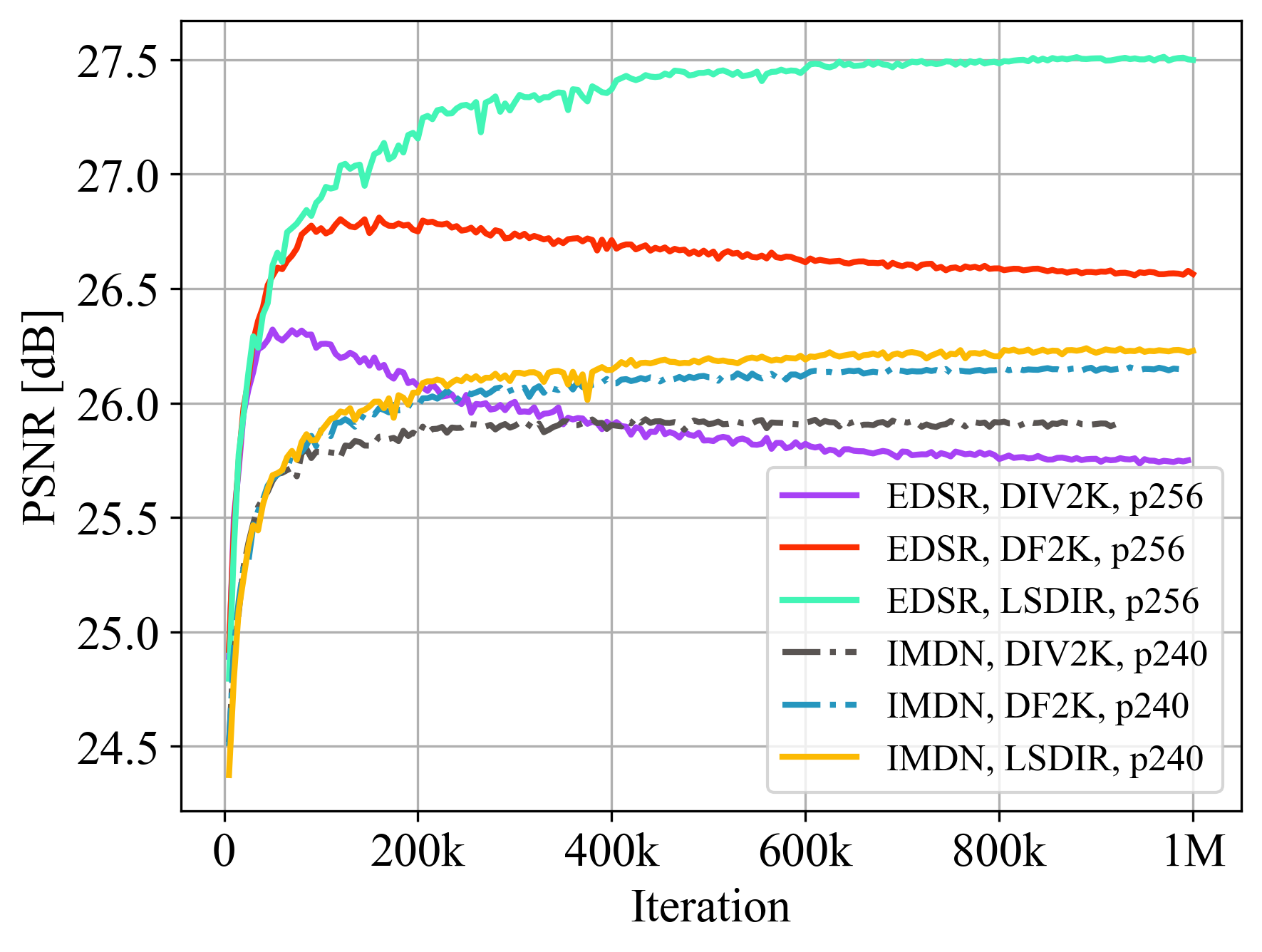
Different datasets with larger training patch size.
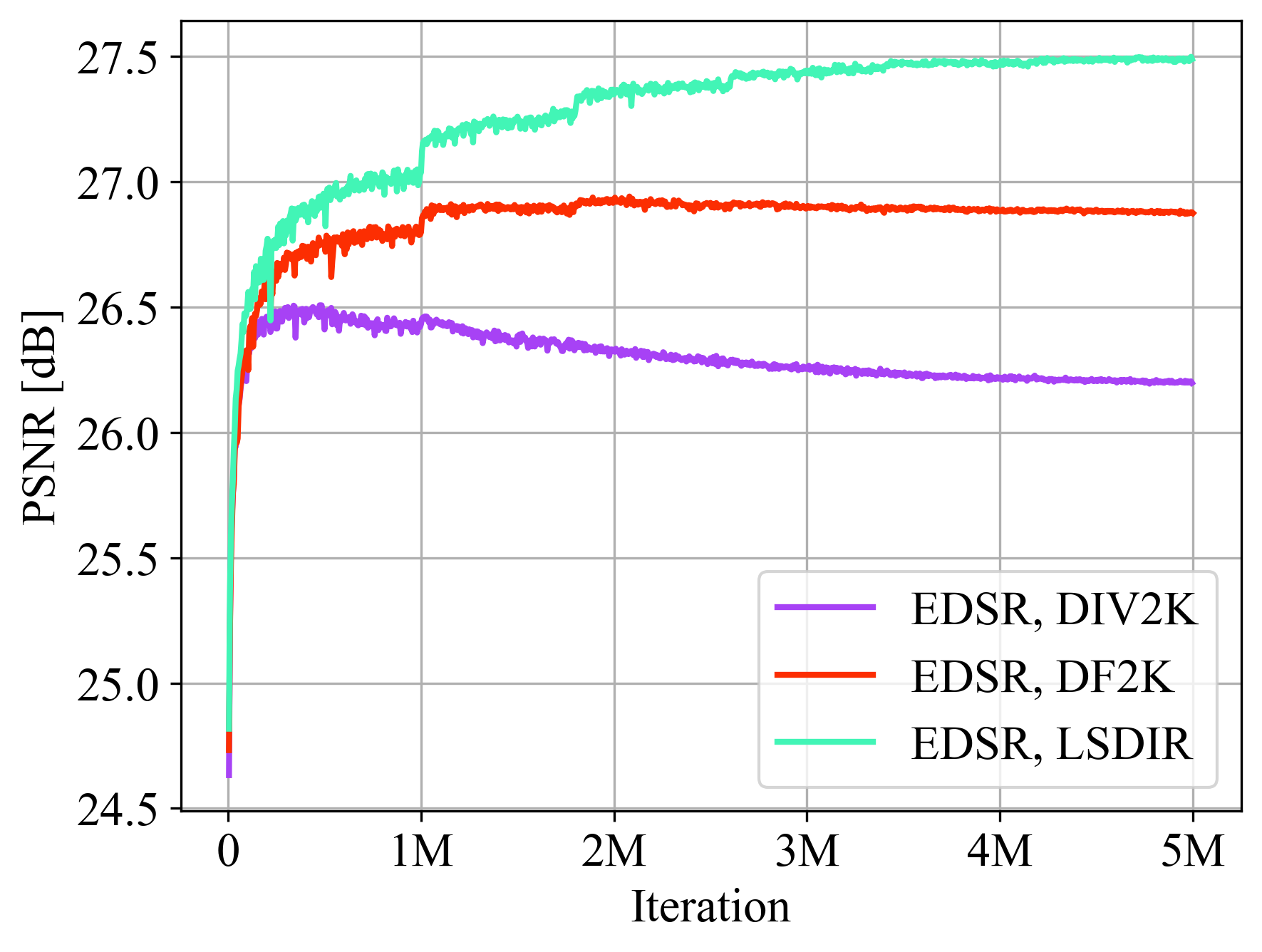
Different datasets with increased training iterations.
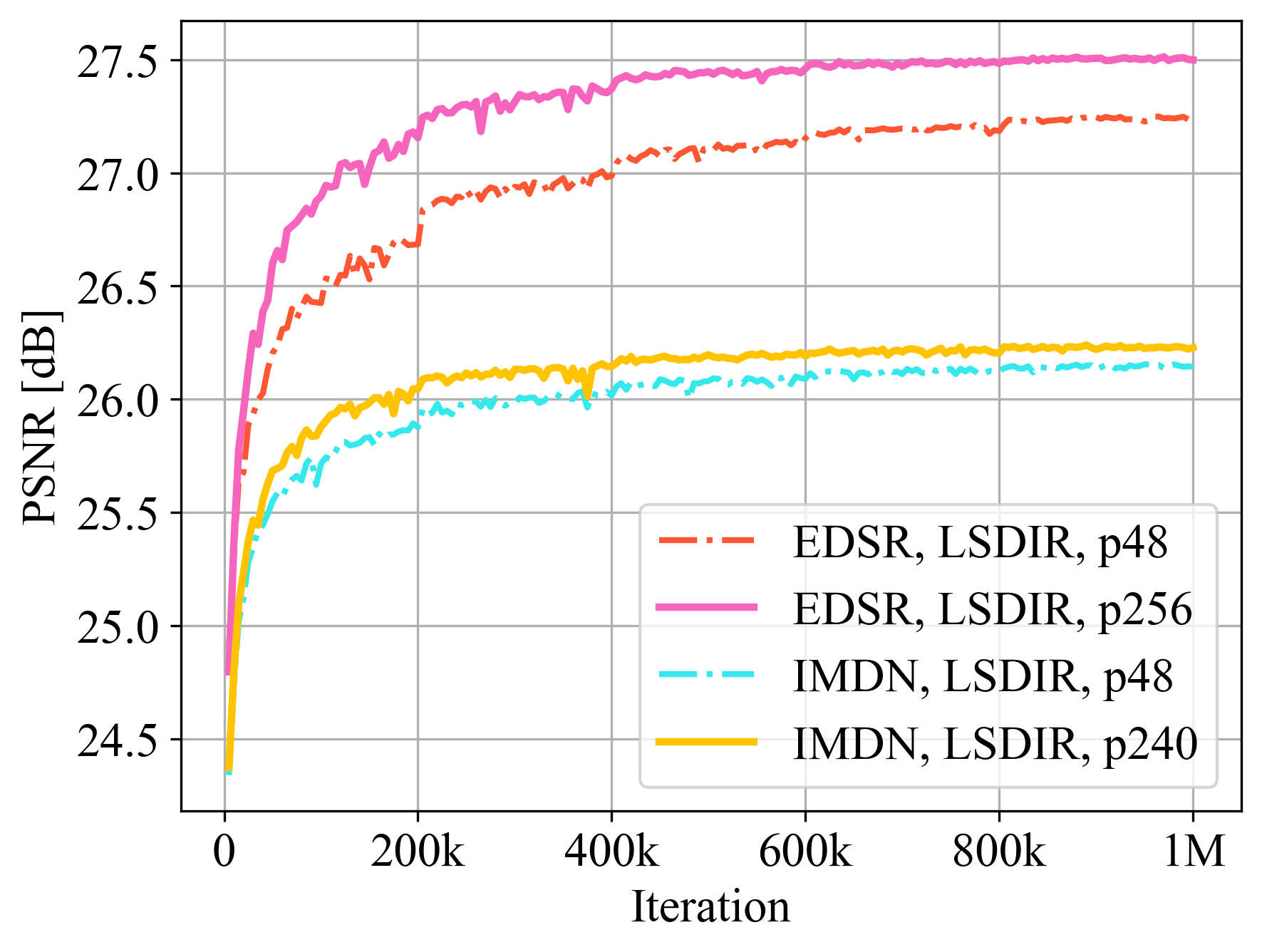
LSDIR training with different patch sizes.
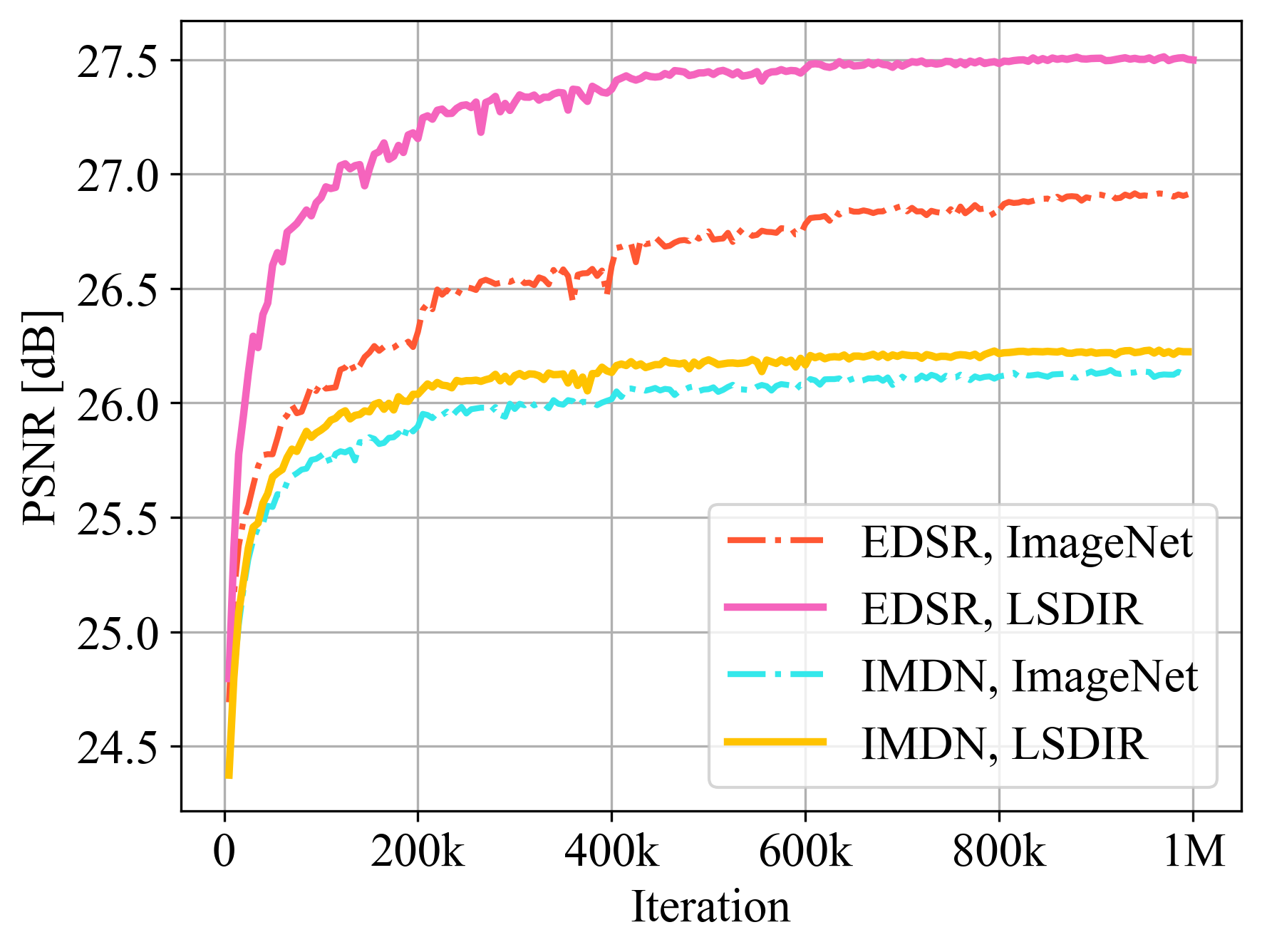
Comparison between LSDIR and ImageNet
Comparison of validation accuracy on the Urban100 dataset between different settings. The experiments are done for image SR with upscaling factor ×4. ‘p*’ denotes the patch size.
Data Overview
We are making available a large newly collected dataset -LSDIR- of RGB images with a large diversity of contents.
The LSDIR dataset is divided into:
- training data: 84,991 high-definition high-resolution training images. We obtain corresponding low-resolution images and provide both high and low-resolution images for 2, 3, and 4 downscaling factors.
- validation data: 1,000 high-definition high-resolution validation images. The validation data will be released later.
- test data: 1,000 high-definition high-resolution test images. We obtain corresponding low-resolution images. This set is used for benchmarking purposes. Thus, only low-resolution images for 2, 3, and 4 downscaling factors are provided. The test data will be released later.
Data Structure
Train
The training data in LSDIR dataset has the following structure:
LSDIR/ -- LSDIR dataset
LSDIR/HR/train/00XX000/00YYYYY.png -- training HR images;
LSDIR/X2/train/00XX000/00YYYYYx2.png -- training LR images, downscale factor x2;
LSDIR/X3/train/00XX000/00YYYYYx3.png -- training LR images, downscale factor x3;
LSDIR/X4/train/00XX000/00YYYYYx4.png -- training LR images, downscale factor x4;
where XX is the split ID ranging from 01 to 85.
The first 84 splits contains 1,000 images and the 85th split contains the rest 991 images.
where YYYYY is the image ID ranging from 00001 to 84991.
Validation
The training data in LSDIR dataset has the following structure:
LSDIR/HR/val/000XXXX.png -- validation HR images;
LSDIR/X2/val/000XXXXx2.png -- validation LR images, downscale factor x2;
LSDIR/X3/val/000XXXXx3.png -- validation LR images, downscale factor x3;
LSDIR/X4/val/000XXXXx4.png -- validation LR images, downscale factor x4;
where XXXX is the image ID ranging from 0001 to 1000.
Data Access
Train
- High-Resolution Images:
- Train Data: shard-00 (HR images)
- Train Data: shard-01 (HR images)
- Train Data: shard-02 (HR images)
- Train Data: shard-03 (HR images)
- Train Data: shard-04 (HR images)
- Train Data: shard-05 (HR images)
- Train Data: shard-06 (HR images)
- Train Data: shard-07 (HR images)
- Train Data: shard-08 (HR images)
- Train Data: shard-09 (HR images)
- Train Data: shard-10 (HR images)
- Train Data: shard-11 (HR images)
- Train Data: shard-12 (HR images)
- Train Data: shard-13 (HR images)
- Train Data: shard-14 (HR images)
- Train Data: shard-15 (HR images)
- Train Data: shard-16 (HR images)
- Low-Resolution Images:
Validation
- 250 validation images from the whole validation set:
How To Use?
Please refer to the GitHub Page.
License
Please notice that this dataset is made available for academic research purpose only. All collection and processing of data for LSDIR was performed by the academic co-authors. All the images are collected from the Internet, and the copyright belongs to the original owners. If any of the images belongs to you and you would like it removed, please kindly inform us, we will remove it from our dataset immediately.